Google DeepMind Unveils Two AI Models for Robotics
 03/17 2025
03/17 2025
 646
646
Produced by Zhineng Technology
Google DeepMind has recently unveiled two new AI models tailored for robotics, Gemini Robotics and Gemini Robotics-ER, both built upon the Gemini 2.0 framework.
These models extend AI capabilities from the digital realm into the physical world, propelling us towards robots that are versatile, interactive, and dexterous.
● Gemini Robotics is an advanced vision-language-action model capable of tackling untrained tasks, interpreting natural language commands, and adapting to environmental changes in real-time.
● Gemini Robotics-ER focuses on enhancing spatial comprehension, supporting cross-platform applications, and improving safety, paving the way for the widespread integration of robots into daily life.
Currently, the technology faces challenges such as sluggish movements and insufficient data, necessitating time before commercial readiness.

01
Gemini Robotics:
A Milestone Towards Versatile Robotics

● Versatility: Breaking the Shackles of Specific Tasks
Robotics technology has long grappled with its inability to adapt to unfamiliar environments. As Kanishka Rao, Head of Robotics Research at Google DeepMind, observes, "Robots typically excel only in scenarios they have encountered before, becoming helpless in uncharted territories."
Traditional robots often rely on pre-programming or task-specific training, causing their performance to plummet when venturing beyond known parameters.
Gemini Robotics, with its remarkable versatility, significantly alleviates this issue. It can operate autonomously in new, untrained tasks and environments.
According to DeepMind's technical report, the model outperforms current state-of-the-art vision-language-action models by over 100% in comprehensive generalization benchmarks.
This breakthrough allows robots to adapt to new objects, diverse instructions, and environments without specialized training for each scenario.

In a demonstration, researchers placed a small dish, grapes, and bananas, instructing the robot, "Put the banana in the transparent container." The robot swiftly identified the banana and container, completing the task. Even when the container's position changed, the robot adjusted in real-time, relocating, and executing the command.
Remarkably, when researchers introduced a toy basketball and hoop, requesting a "slam dunk," the robot understood and executed the action, despite never encountering these objects before.
These examples vividly showcase Gemini Robotics' generalization ability, marking a significant step towards versatile robots.
● Interactivity: Natural Language and Real-Time Adaptation
Another key strength of Gemini Robotics lies in its interactivity.
○ Leveraging Gemini 2.0's robust language understanding capabilities, the model responds to everyday conversational language instructions and supports multilingual communication.
Users need not employ professional terminology or a fixed command format; they can simply converse with the robot in natural language. For instance, a user might say, "Help me put the grapes on the table into the lunch box," and the robot will comprehend and execute the command.
○ It adapts to environmental changes in real-time, continuously monitoring the surroundings, detecting changes in object positions or unexpected situations, and swiftly adjusting its actions. For example, if grapes slip from its grasp or the container is moved, the robot can replan its path and continue with the task.
This dynamic adaptability is crucial for functioning in the highly unpredictable real world, making Gemini Robotics more practical for human collaboration.
● Dexterity: Achieving Fine Manipulation
Dexterity is a crucial measure of a robot's practicality. Many everyday tasks humans perform effortlessly, such as folding paper or packing snacks, are highly challenging for robots. Gemini Robotics excels in this area, demonstrating robust fine motor control.
○ It handles complex multi-step tasks requiring precise manipulation, such as folding paper or packing snacks into sealed bags. In demonstration videos, the robot completes paper-folding tasks through coordinated arm movements, requiring not only precision but also hand coordination and an understanding of physical materials.
○ It can also pack lunch boxes into bags, demonstrating proficiency in soft object manipulation and force control. These abilities indicate that Gemini Robotics can perform tasks at both macro and micro levels, opening up application possibilities in fields like home, healthcare, and industry.
● Technical Foundation and Training Methods
Gemini Robotics is a vision-language-action (VLA) model that adds physical action output to Gemini 2.0 to directly control robots. Its training data originates from various sources, including synthetic data from simulated environments and teleoperated data from the real world.
○ In simulated environments, the robot learns physical rules, such as not passing through walls.
○ Through teleoperation, humans guide the robot to complete real-world tasks.
○ DeepMind is also exploring the use of video footage to further enrich training data.
This multimodal training approach provides a solid foundation for the model's versatility, interactivity, and dexterity.
02
Gemini Robotics-ER:
A Pioneer in Spatial Understanding and Multi-Form Adaptability

● A Breakthrough in Spatial Understanding
Gemini Robotics-ER, a sister model to Gemini Robotics, focuses on enhancing spatial understanding.
It significantly improves Gemini 2.0's pointing and 3D detection capabilities, enabling robots to perceive the physical world more intuitively and plan actions. For instance, facing a coffee cup, the model can identify a suitable two-finger grasp and calculate a safe approach trajectory.
This ability not only relies on understanding object shapes but also involves reasoning about spatial relationships and action consequences.
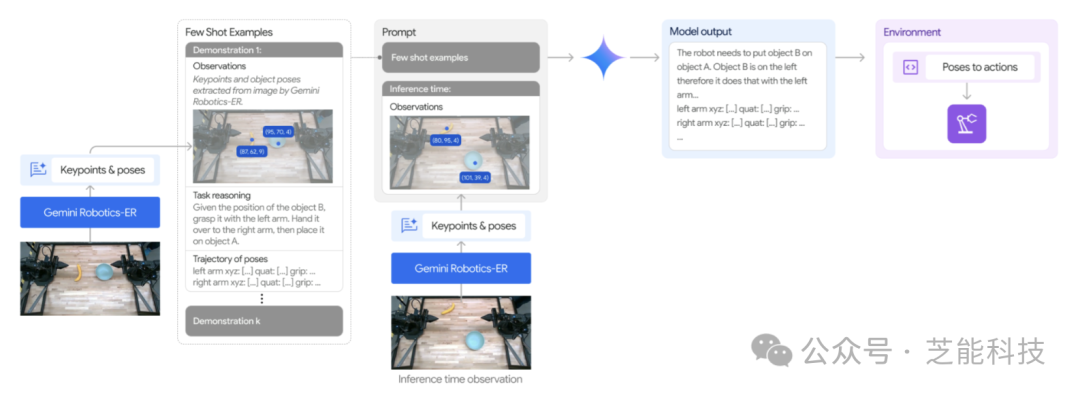
This enhanced spatial understanding allows Gemini Robotics-ER to excel in complex environments, handling tasks requiring high spatial reasoning, such as navigating crowded spaces or manipulating nested objects.
This breakthrough offers a powerful tool for robot researchers, enabling integration with existing low-level control systems to further optimize robot performance.
● Multi-Form Adaptability and Application Prospects
Another notable feature of Gemini Robotics-ER is its multi-form adaptability.
While primarily trained on the ALOHA 2 dual-arm robot platform, it can also control platforms based on Franka robotic arms and adapt to more complex carriers, like the humanoid robot Apollo developed by Apptronik.
This cross-platform capability significantly broadens its application scope, encompassing industrial robots, service robots, and even humanoid robots.
For example, in collaboration with Apptronik, Gemini Robotics-ER serves as the "robot brain" for the Apollo humanoid robot, demonstrating its potential in complex forms.
Furthermore, through the "Trusted Tester" program, Google provides limited access to companies such as Boston Dynamics and Agility Robotics, accelerating technology validation and optimization across different scenarios. This flexibility opens up possibilities for diversified robot technology development.
● Safety: Comprehensive Safeguards from Low-Level to Semantic
As AI ventures into the physical world, safety becomes a paramount concern. DeepMind employs a hierarchical approach to ensure safety, spanning from low-level motor control to high-level semantic understanding.
○ Gemini Robotics-ER interfaces with specific robots' low-level safety controllers to ensure movements adhere to physical safety standards, such as avoiding collisions or limiting contact force.
○ At the semantic safety level, Google has released the ASIMOV dataset to evaluate and improve embodied AI's safety performance. The dataset contains various scenarios requiring robots to assess action safety, like "Is it safe to mix bleach with vinegar?" Gemini Robotics-ER performs well in this benchmark, capable of identifying potential risks.
Inspired by Isaac Asimov's "Three Laws of Robotics," DeepMind has developed a constitutional AI mechanism for the model, optimizing responses through self-criticism and feedback to prioritize human safety.

Summary
The Gemini Robotics and Gemini Robotics-ER models unveiled by Google DeepMind lay the groundwork for achieving autonomous versatile robots through breakthroughs in versatility, interactivity, and dexterity. Meanwhile, Gemini Robotics-ER, with its spatial understanding and multi-form adaptability, enhances robots' potential for application in complex environments. Improvements in safety design further bolster the technology's reliability. Both models are still in their nascent stages, facing challenges like sluggish movements, limited learning capabilities, and insufficient training data, and there are currently no clear commercialization plans.
-
![]()
Model Giant Jieyue Xingchen Steps into Smartphone Arena: A Strategic Alliance with Huaqin Technology
-
![]()
Big Model Firm Dives into Phone Market: StepFun and Wingtech Forge a ‘Dynamic Duo’
-
![]()
Zhongrun Optics Makes a Bold Move with 1 Billion Yuan Investment: Is a Turning Point on the Horizon for the Precision Optics Industry?
-
![]()
Deploy CLBO Crystals and YIG Single Crystals! Erythritol Leader Invests 30 Million in Youwei Optoelectronics
-
CXMT’s July 16 Subscription: Leading Domestic Memory Manufacturer—What’s the Earning Potential per Lot?
-
![]()
Rhythm Discrepancy and Premium Value Erosion: Foreign Luxury Brands Must Re-evaluate Their China Strategy
-
![]()
Half-Year, 1 Billion Yuan Financing, 7 Billion Yuan Valuation: A New Dark Horse Emerges in the Embodied AI Sector
-
![]()
Strong Rebound for Tech Stocks in Hong Kong Stock Market: Is It Time to Bottom-Fish?