AMD's AI Developer Day: Computing Power Competition Enters the Era of Local Agents
 05/20 2026
05/20 2026
 535
535

Produced by Zhineng Zhixin
AMD AI DevDay 2026, held in Shanghai, attracted over two thousand developers, with the venue packed with attendees.
As AMD's Shanghai R&D Center celebrates its 20th anniversary, the competition for AI computing power is shifting from 'who has more GPUs' to 'who can enable developers to run agents at lower costs, more locally, and more continuously.'

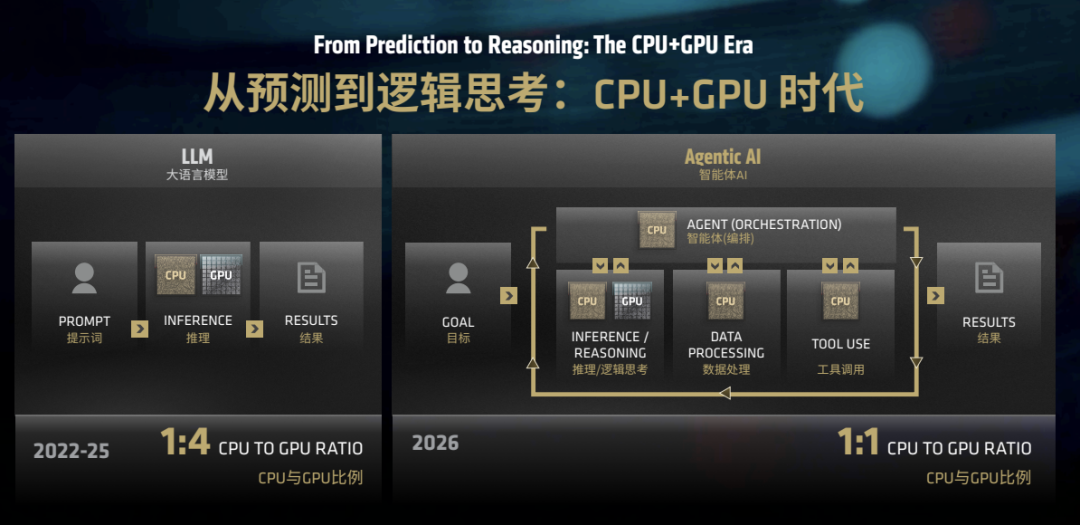
This marks the first time AMD's AI Developer Conference has come to China, as AI development enters a new phase. Previously, the focus was on training large models, requiring substantial GPUs, clusters, and cloud computing power.
Now, the challenge has changed. Agents need to operate continuously, invoke tools, process enterprise data, maintain local privacy, and allow developers to repeatedly test, tune parameters, and deploy.
This shift has dispersed computing power demands from a single central hub into multiple nodes.
While the cloud remains crucial, edge devices, local workstations, developer machines, and enterprise internal deployments are regaining importance.
AMD sees its opportunity here, aiming to connect CPUs, GPUs, NPUs, unified memory, the ROCm software stack, and developer tools into a seamless pathway from local development to data center deployment.
Part 1
AI Demand Shifts: From Large Model Invocation to Continuous Local Agent Operation
The core backdrop of this conference is the evolving scale and invocation methods of AI usage.
Lisa Su mentioned in her speech that there are now over 1 billion active AI users globally, with expectations to exceed 5 billion in the coming years. AI will transition from a tool for a few enterprises and developers to a near-universal computing need, with its form evolving as well.
Previously, large model applications operated on a 'question-answer' basis. Now, agents perform sequences of actions rather than single invocations.
A coding agent generates, checks, modifies, and tests code before regenerating it.
An enterprise agent reads data, invokes APIs, generates conclusions, triggers processes, and continuously feeds back.
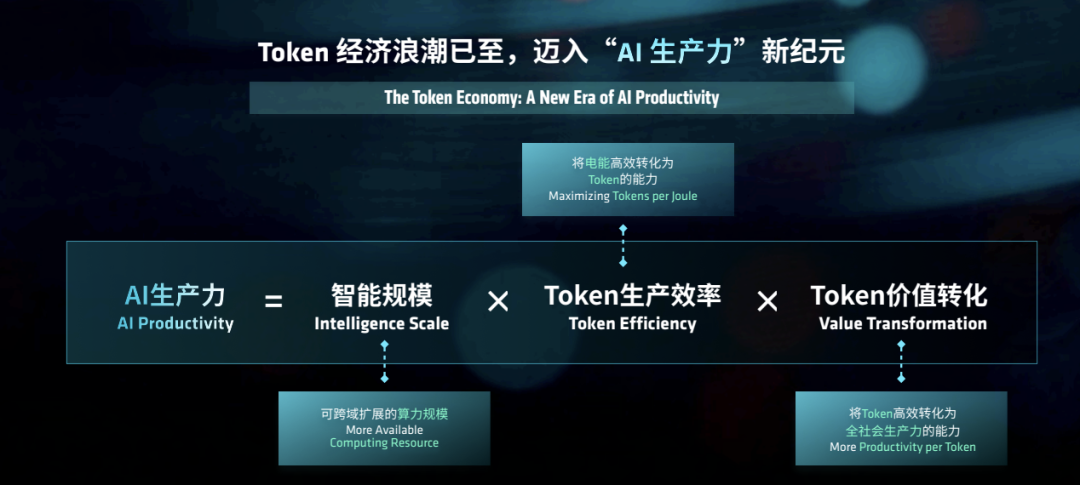
This raises an issue: token demand will rise exponentially. OpenCode Router's tokens grew from 2 trillion in February 2025 to 42 trillion in February 2026, with China using 140 trillion tokens daily—a more than 100-fold increase in two years. AI costs are expanding from 'model training costs' to 'daily inference costs.'
Enterprises are no longer just spending once on model training but continuously consuming computing power with every invocation, agent cycle, and toolchain collaboration.

For enterprises, AI must move beyond the lab and impact revenue, profits, compliance, dynamic pricing, supply chains, time-to-market, and organizational efficiency—otherwise, it remains just an AI lab project.

The same applies to developers. Future competition won't be about 'which API I use' but 'whether I can embed agents into business processes at lower token costs.'
This is why local AI is regaining attention. If all development, testing, and internal data processing rely on cloud APIs, costs, privacy, latency, and controllability become bottlenecks.
If some inference can run locally, developers gain three advantages:

◎ First, cost control. After purchasing local machines, there are no ongoing charges per token or session.
◎ Second, enhanced data security. Enterprise knowledge, meeting records, R&D materials, and customer data don't need to be uploaded to the cloud each time.
◎ Third, faster iteration. Without network, quota, or external service restrictions, developers can debug agents more frequently.
AMD's 'Agent Host' redefines the role of AI PCs—can a local device continuously run one or more agents, support complex models, and serve as a personal and enterprise local AI gateway?
Part 2
AMD's Strategy: Using Ryzen AI Max+ to Establish Local Agents as a New Hardware Category
AMD's clearest product focus at this event is the Ryzen AI Max+ series. With the rise of AI agents, AMD pioneers the 'Agent Host' concept, requiring dual-engine computing power (CPU+GPU) along with high-bandwidth, large-capacity unified memory.

Agents don't just run a single model; they handle inference, tool invocation, data retrieval, multimodal input, context management, and local application interactions simultaneously.
Agent hosts based on AMD Ryzen AI Max+ processors now come in all-in-ones, laptops, and Mini AI workstations.
HP, ASUS, Lenovo, Acer, and local emerging brands have launched over 35 related product designs.
These systems support up to 96GB of dedicated GPU memory and can natively run models with up to 200B parameters, such as Qwen 3.5 122B, locally at high performance.


The biggest issue with local AI in the past was that it could 'run' but wasn't user-friendly. Small models lacked capability, while large models exceeded memory capacity.
Once models require splitting, offloading, or frequent external memory access, the user experience declines significantly.
AMD's emphasis on unified memory and large memory addresses the barriers to running large models locally, allowing developers to develop, test, fine-tune, and validate agent prototypes without immediately relying on expensive cloud production environments.
This is particularly crucial for Chinese developers, given China's AI ecosystem's abundance of open-source models, application developers, and local deployment needs. If developers can run larger models on their laptops or workstations for prototype validation around agents, RAG, multimodality, code generation, and enterprise private data, the ecosystem's pace will accelerate significantly.
This represents AMD's opportunity to capture the developer entry point.
Previously, GPU competition revolved around data center races—securing major clients, delivering large clusters, and supporting training.
However, in the agent era, the developer entry point shifts earlier. A developer might prototype locally using Radeon AI PRO or Threadripper PRO, test and deploy at a small scale, and later migrate to data center GPUs.
Using the same software stack throughout this pathway minimizes migration costs—this is the 'local-to-data center' continuity.
Part 3
ROCm Aims to Enable Development Pathways from Laptops to Data Centers
AMD's biggest historical weakness in AI has been its software ecosystem, which is why the conference repeatedly emphasized ROCm.
The AMD ROCm open-source software platform has expanded at the product and system levels, now supporting the new-generation AMD Ryzen AI 400 series processors and available for download in ComfyUI.
Starting with ROCm 7.2, compatibility has expanded to Windows and Linux, with new PyTorch versions also accessible via AMD software for efficient deployment on Windows.

◎ First, Windows support means more PC-side and creator environments can participate. Many local AI applications run not just on Linux servers but on developers' personal computers, workstations, and creative toolchains.
◎ Second, ComfyUI support indicates AMD's entry into image generation and multimodal developers' daily workflows.
◎ Third, PyTorch and ROCm integration reduces friction around 'whether it can run.' Developers fear not theoretical performance gaps but high costs in installation, drivers, dependencies, framework adaptation, and debugging.
ROCm serves as a unified software platform supporting all AMD GPUs, enabling interoperability from laptops and workstations to data centers.
Through the HIPCC compiler, ROCm libraries, AI frameworks like PyTorch, and agent frameworks like OpenClaw, AMD aims to achieve 'write once, run everywhere.'
Beyond ROCm, AMD connects local development with professional workstation pathways.
The AMD Radeon AI PRO R9700, based on AMD RDNA 4 architecture with 32GB memory, targets local AI inference, development, and memory-intensive workloads.
The AMD Ryzen Threadripper PRO 9000 series supports up to 128 PCIe 5.0 lanes for multi-GPU and NVMe storage configurations, suitable for local AI fine-tuning, inference, and application development.

◎ Layer 1: Ryzen AI Max+ addresses local agent and large model prototyping for developers.
◎ Layer 2: Radeon AI PRO and Threadripper PRO handle workstation-level testing, fine-tuning, and development.
◎ Layer 3: Data center GPUs and the unified ROCm software stack manage larger-scale deployments.
If these three layers interconnect, AMD won't just sell chips but an entire development pathway.
AMD is also advancing its ecosystem in China through initiatives like the Radeon GPU Free Developer Cloud, collaborations with foundational model companies, Alibaba Cloud's model community, and creation spaces. Ultimately, AI hardware competition hinges on developers—enabling them to iterate faster can transform hardware advantages into ecosystem advantages.
Summary
In the agent era, computing power resides not just in the cloud but at developers' fingertips. Local AI hosts, workstations, and unified software stacks will form the new infrastructure layer.
-
![]()
The Surprisingly Significant Impact Difference Between Quiet and Noisy Cars!
-
![]()
Breaking Through Storage Cycle Barriers: How AI Large Models and Coding Technology Synergize to Drive Transformation in the Security Industry
-
Facilitating the Slimming of Camera Modules! O-film Obtains Utility Model Patent for Periscope-Type Reflective Component
-
![]()
Hikvision Raytine’s Millimeter-Wave Body Imaging Security Inspection Device Achieves ECAC SSc Category A Standard Level 2.1 Certification for European Civil Aviation
-
![]()
Global Market Share for Security Windows Hits 26%! This Optical 'Little Giant' Makes Its Debut on NEEQ
-
![]()
The Evolutionary Path of Agent Engineering: From Prompt to Harness by Zhang Yutao, Co-founder of Moonshot AI
-
![]()
Profits and stock prices are both declining, so why are executives from these auto companies increasing their purchases?
-
![]()
Burning Tens of Billions of Dollars, Yet No Unified Definition for World Models